
An audio-driven generative system that transforms sound into persistent, evolving crystal structures. Not as a waveform to display, but as a growth process. Rather than clearing each frame, the canvas accumulates indefinitely. Sound leaves permanent, non-reproducible traces shaped entirely by the temporal structure of the input.


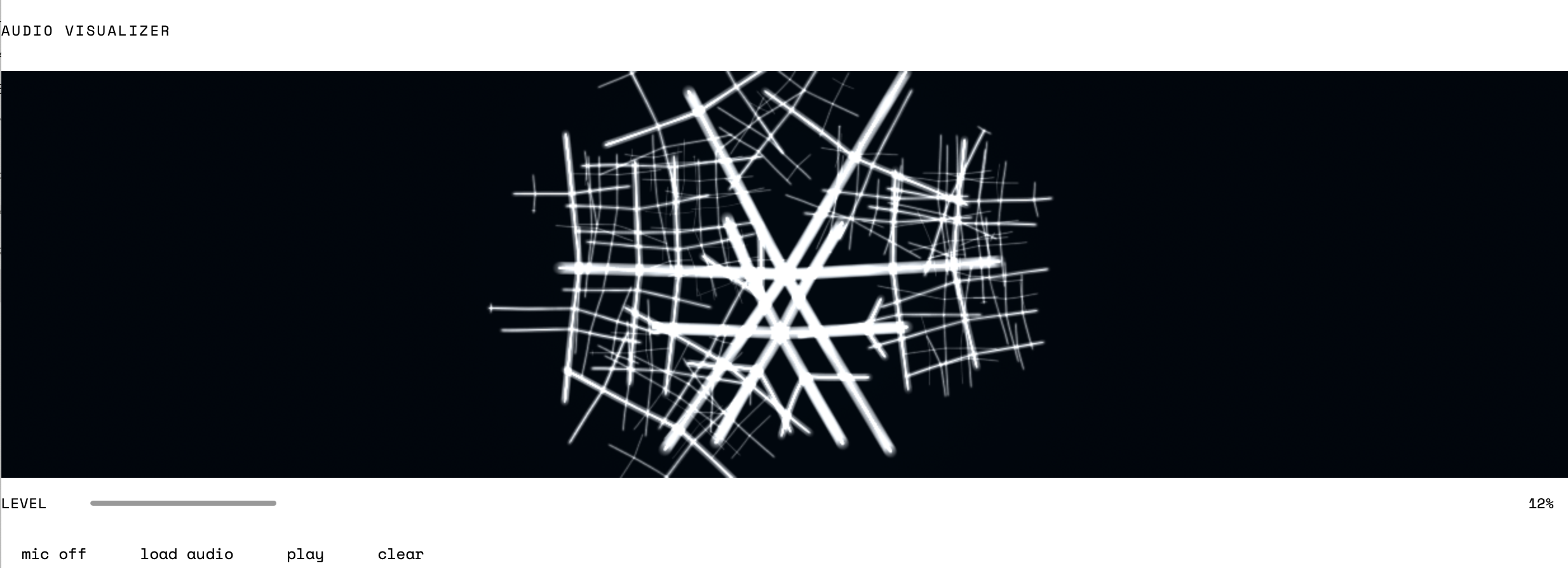
Audio is analyzed in real time via FFT (Web Audio API), extracting three signals per frame: energy (overall activity), bass (~43–473 Hz), and treble (~1828–5590 Hz). These route into two parallel growth systems.
Bass drives dendritic branching through directional agents called crystal tips, each carrying a direction vector, a fuel value, and a branching timer. They move forward, drift in angle, and split into child tips as they exhaust their fuel. The resulting structures are dendritic and crystalline: rigid, hierarchical, self-similar. Treble triggers arc behavior: conjugate pairs with a shared center and radius, one clockwise and one counter-clockwise, that converge into closed rings. Balanced input between bass and treble produces hybrid snowflake-like morphologies where both systems operate simultaneously and overlap.
A density feedback loop monitors canvas saturation and shifts the render mode from bright additive drawing to dark layered accumulation as the composition fills. The piece changes phase as it develops.
The branching model is directly informed by Diffusion-Limited Aggregation (DLA), a growth model first described by Witten and Sander (1981) in which particles undergoing random walks cluster upon contact, producing the branching, fractal geometries characteristic of snowflakes, frost, and mineral dendrites. In ice crystal formation, the specific morphology (needle, plate, dendrite, column) is determined by local temperature and humidity at the moment of growth, not by a global blueprint. Kenneth Libbrecht's work at Caltech (The Physics of Snow Crystals, 2005) documents how marginal differences in atmospheric conditions during growth produce structurally distinct outcomes from identical starting conditions. This system operates on the same principle: the same code, different audio input, produces irreconcilably different structures. The canvas becomes a record of conditions rather than a designed composition.
Applied to speech or conversation, differences in tone, rhythm, and frequency produce structurally distinct visual fingerprints. No two sessions are the same, not because of randomness, but because the temporal structure of sound is genuinely unique each time. Less visualization, more deposit.
The next step is replacing digital audio with physical signal input: contact microphones, vibration sensors, or microcontroller-based setups, allowing the system to respond to real environmental sound and physical vibration rather than processed audio. The longer-term direction is using the system as a tool for reading and archiving physical space through the structures sound leaves behind.